Overview
LLM-powered Alpha Factor Mining
Alpha factors are mathematical expressions derived from market data (price, volume, fundamentals) that predict future stock returns — the core building block of quantitative investment strategies. Mining effective alpha factors has traditionally required deep domain expertise and exhaustive manual search.
Large Language Models offer a promising paradigm shift: they can encode financial knowledge, generate factor candidates from natural language descriptions, and iteratively refine formulas with execution feedback. AlphaBench is the first systematic benchmark to rigorously evaluate LLMs across the entire formulaic alpha mining workflow — from generation to evaluation to iterative searching.

Figure: Overall benchmark — AlphaBench evaluates LLMs across the full formulaic alpha mining workflow using real financial data and task-aligned quantitative metrics.

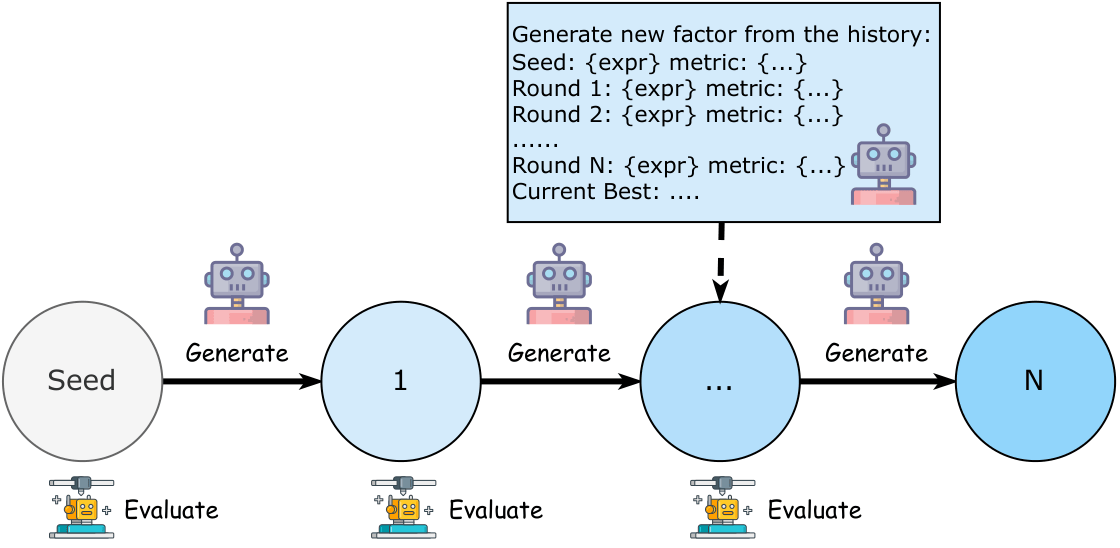
Figure: Task description — AlphaBench decomposes alpha mining into three core tasks: factor generation, factor evaluation, and iterative factor searching.
Critical Tasks We Care
Direct Factor Generation
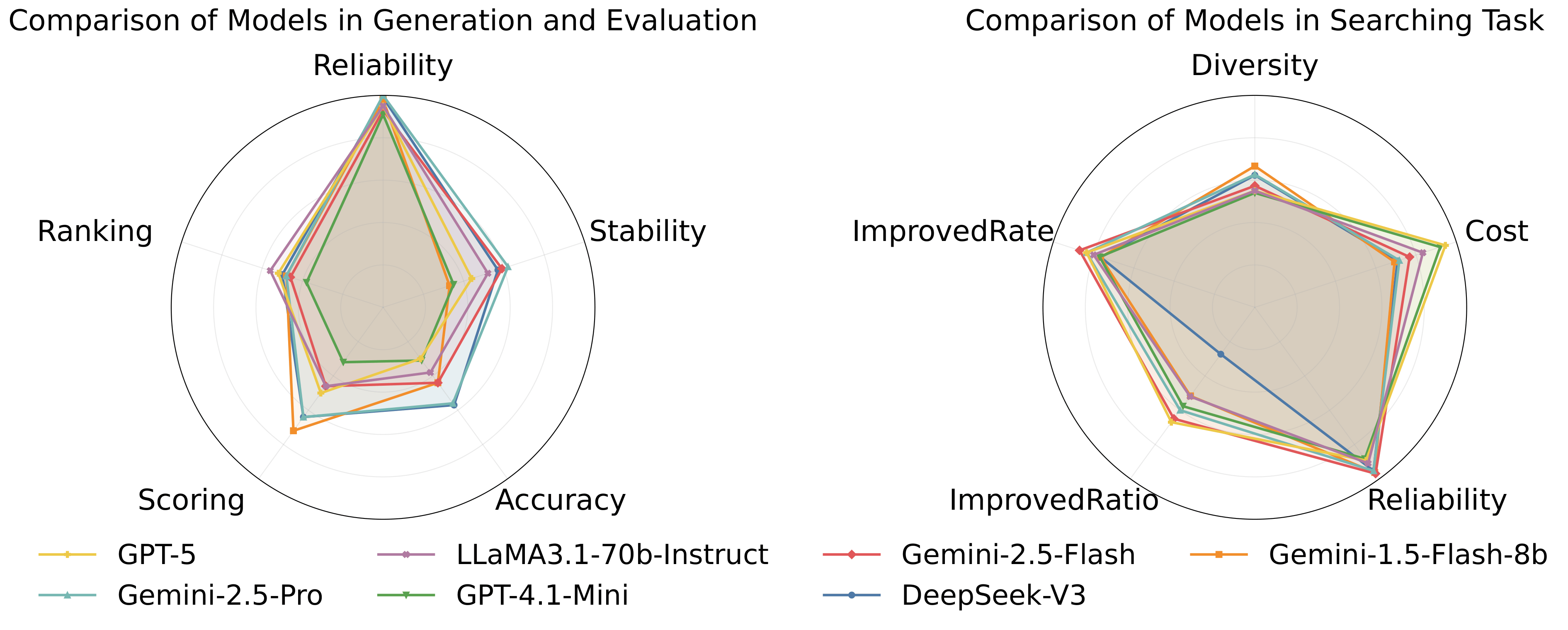
Can LLMs translate financial concepts into executable alpha factor formulas? We probe two scenarios: (1) Text2Alpha — converting a textual description (e.g., "5-day momentum adjusted for volatility") into a syntactically valid formula; (2) Directional Mining — generating a diverse set of factors under a given semantic direction (e.g., "volatility-based"). We measure reliability, output stability, and semantic alignment.
Can LLMs Go Beyond Backtesting?
Running a full backtesting simulation is expensive. We ask: can LLMs act as zero-shot judges and predict factor quality without executing the formula? This includes ranking a candidate pool to select top-K factors, and scoring each factor on multiple quality dimensions — IC, RankIC, robustness, win rate, and skewness. Our findings reveal this remains the weakest capability of current LLMs.
LLMs Adaptive to Mining Algorithms
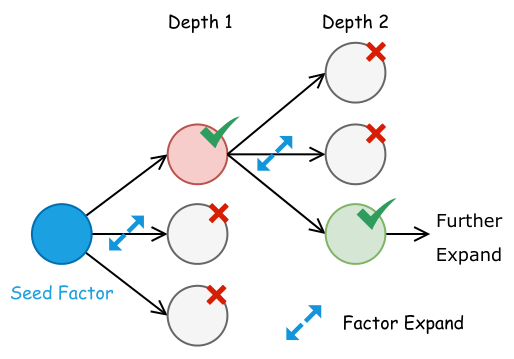
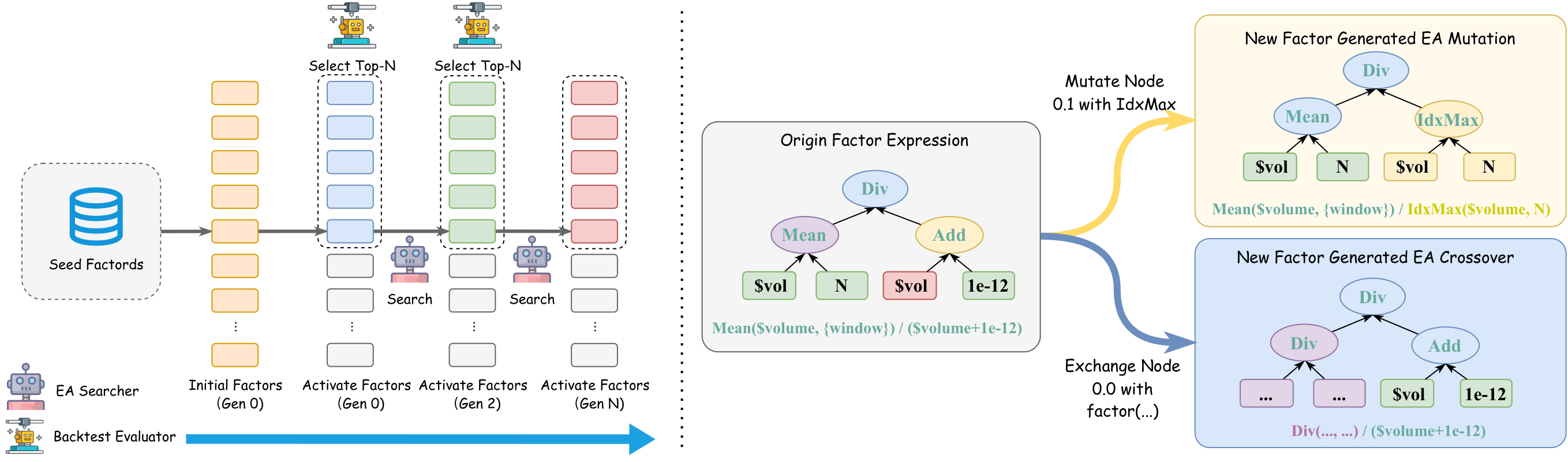
Different searching algorithms make different demands on LLMs. We evaluate LLMs as components within three paradigms: Chain-of-Experience (sequential refinement), Tree-of-Thought (branching exploration), and Evolutionary Algorithms (population-based mutation & crossover). We provide standardized baseline implementations and compare search quality, cost efficiency, and factor diversity across all three approaches.